3.X Reference Docs
NEWS
Scrubber now uses Apache cTakes to provide parallel concept extraction during de-idenification. Apache cTAKES graciously invited us to port the Scrubber de-identification pipeline to the Apache hosted codebase. The maintenance version of the 2.X will remain available as will the 3.0 release candidate. The publication describing this work has been accepted, this site will be updated shortly to reflect the described methods and results.
McMurry* AJ, Fitch* B, Savova G, Kohane IS, Reis BY. “Improved de-identification of physician notes through integrative modeling of both identifying and non-identifying medical text”, BMC Medical Informatics and Decision Making Accepted Jan 2013.
Overview
3.X is a new vision for the scrubber. As we approached diminishing returns for improving REGEX and whitelists/black lists, we have shifted towards a machine learning methods approach and learning from large bodies of medical information from publications and UMLS dictionaries.
Venn Diagram
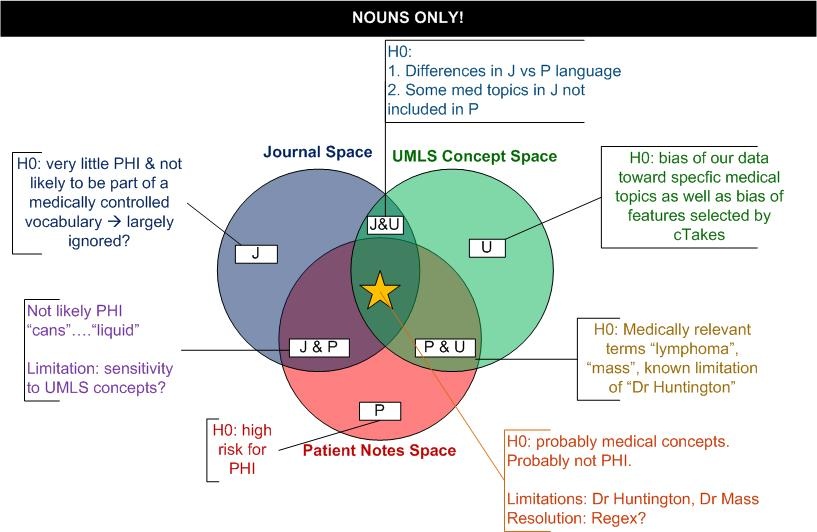
Use Case: Tagging Noun Phrases and UMLS concepts
Precondition:
- Training Data
- Software: cTakes using features POS tagger & UMLS CUID extractor
Steps:
- Block of text is sent to cTakes
- cTakes processing
- start & end position of all POS tags
- part of speech
- Most interested in Nouns because of PHI
Post-condition:
- Input document (either medical note OR publication) POS tagged and medical concept CUIDs.
Use Case: Meta-analysis of text
Precondition:
- Tagging Noun Phrases
- Scubber configured (with or without local dictionary/regex mods)
Steps:
- Each "scrubber" implementation procudes Recorder output
- Passthrough Imp
- Regex
- Word lists
- cTakes Impl (OpenNLP)
- Noun Phrases
- UMLS cuids
- Passthrough Imp
- Performance evaluation (ROC)
- Scrubber standalone
- Scrubber word lists limited by detected noun phrases
- Scrubber word lists limited by detected noun phrases and non-UMLS concepts
Post-Condition
- Text is processed by more than one algorithm "ham vs spam"